Another way of organizing variables
-
OK, trying to sort things out in the Units thread causes me to rethink the whole architecture, at least in an exploratory way.
This is an early sketch of this approach.
Suppose our addressing was:
There are 1...N_NODES nodes which can send and receive packets Each node can have 1..N_CHILDREN children, sub groups of variables within the node Each child can have 1..N_VARS variables Each variable can have 1..N_SUBVARS sub-variables (AVG, MIN, MAX, etc)Each level can report the number of items below it, and each item can describe itself as needed. So you can find out from a node how many children it has and address each one by child_id. You can address each child and find our how many variables it has. You can set or retrieve values or config information about each variable using the variable index (within the child within the node).
Some variables have accumulation-period defined subvariables, also indexable, like SUM, AVG, MIN, MAX., These are really separate measurements but optional derived values.
There is no need for variable 2 of child 1 of a given node to send its V code and S code every time. The hub has saved the V and S type for that variable.
The child level is not strictly needed here. The node could just have a single list of all variables (for all sensors and actuators). The purpose of having a child level is to group variables into containers for organizing purposes.
One a node has finished joining the network, the hub will know all the children, variables, and subvariables it supports, for reporting ro the hub or for being set by the hub. (Versus: it finds out that a child exists only when that child first sends a report, and that a variable exists only when that variable is first reported).
How does the hub (central authority, whether implemented in a a gateway or a controller) know all this about the nodes? There are several options:
-
When the node joins the network, the hub could query it, enumerating and getting descriptions for each level, and store that in its own memory.
-
The node could encode all of its substructure in a blob (perhaps kept in PROGMEM, or generated dynamically in a RAM buffer) and stream that to the hub during the join process. The hub can parse that (easily) into the structure it saves representing that node.
-
The hub could have a config file (or blob stored in its memory) from which it gets the information.
Different approaches to getting this setup info to the hub could be used in different versions of the protocol or in different systems, without changing the rest of the protocol.
Advantages:
Hub gets full knowledge of all substructure within a node during join process.
We can have more than one variable of the same type within the same Child. That is, both variable 0 and variable 1 can be type V_LEVEL and S_TEMPERATURE and yet be distinct from each other, because they are identified by their 0 based index within a given child, rather than being addressed by type within a child. For example input temp and output temp for a furnace or floor level and ceiling level temp.
We don't need to send S and V (and maybe even format) metadata in the header with each set or report packet; those are known to both sides already. Instead the packet just identifies the variable (one byte or less) within the child (one byte or less).
Because of that we can afford to track more metadata about a variable, not just the current S and V codes.
This allows us to rethink the per-variable metadata taxonomy. Some of the current difficulty is based on trying to conflate multiple levels of structure and semantics into two code lists.
In organizing the taxonomy it's helpful to separate it into one or more lists of mutually exclusive types (think radio boxes - choose exactly one) and one or more lists of optional attributes (think checkboxes - choose zero or more), as well as possible numeric or t
extual attributes.For example, suppose each variable could have the following:
Choose one: Structure: binary, multistep, percentage, continuum, circular... (V codes overlap with this)
add "command variable" to this list, see another post (eg: reset, start scene...)Choose one: Dimension and default units (S codes are partly used for this now, but also fold in other things)
Optional flag: Uncalibrated means units are arbitrary but monotonically increasing in direction standard units do
Optional flag: sum type "snapshot" accumulation sub-variables available (eg: temp, humidity)
Optional flag: avg type "increasing" accumulation sub-variables available (eg: kwh, flow)
One could even add a name, like "WaterTempIntake" which conveys some information totally unavailble otherwise, even if not in a machine readable structured way yet.
It would even be possible to add the "Scaling factor" value to the metadata, as described before (ie: multiply the reported value by this to get standard unit".
Not having to pass 100% of your metadata with each value frees us up to do a better job with it.
-
-
One could even rethink the child-id (used for grouping related variables) at this point. Instead of being part of the addressing and passed in every packet, what if you consider child-id as metadata associated with the variable. List 0 indexed variables directly from the node, with no child-id in the packet. Instead the child id would be part of the metadata associated with each variable.
So for example, the hub could know that node 52 variable 4 and variable 6 both have attribute child-id 3 so they are grouped in the same container. (remember the three potential ways to get that and other metadata to the hub? That's a separate decision).
OK, so now from the node id (one byte in the network header) and variable index within the node (one byte, used when setting, requesting or reporting values), the hub can know the S and V codes (or cleaned up replacements) and the child ID, and various other optional attributes - none of which need to be passed in every packet any more! The OTA protocol has become small and dead simple. Metadata which dosen't change dynamically is all acquired once during network joining (whether it passes OTA from the node or is looked up in a config file on the hub.
-
OK, there's one other kind of metadata data currently passed within the packet - format or binary encoding of the values. For example 1, 2, 4 byte signed or unsigned ints, or 4 byte float, or string.
The S and V codes, and the child-ID, associated with a variable on a sensactuator node are pretty much static metadata. They don't need to change dynamically during normal operations, so they don't need to be passed in the packet with the value updates.
What about the format? Is there any need to dynamically switch a given variable's format, so in one packet it's a two byte in and in the next packet it's a 4 byte int? Or it varies from a string to a binary float from packet to packet?
I can think of use cases, like trying to keep packet size down and dynamically sending the smallest int size that the current value would fit in. I'm not sure that's really needed tho.
If not, then the OTA format (or encoding) of a variable could be in static metadata too, rather than being passed with every packet.
-
There was other discussion about making the job of the sniffer more difficult.
This approach requires a sniffer to also know the static metadata to full display packet contents.
Three ways of getting the static metadata to the hub were discussed above - the hub fetching by enumeration from the node, the node streaming a full description blob to the hub, or using config files on the hub.
In the former two variants, a sniffer could listen in when a node is joining the network and get everything it needs, or perhaps the node could be willing to be enumerated or to send the blob again - when queried by an active sniffer. Whether the node allows that after the initial join is still to be determined - or might be configurable.
If the hub fetched the metadata from a config file, then either the sniffer would need access to the same file, or the hub could implement a metadata request to allow an active sniffer to do a better job.
Just some thoughts.
-
@Zeph
Trying to take in everything you've posted but it is quite hard to follow the long internal "discussions" and find the gems sometimes :). Could you perhaps try to summarize, and illustrate your ideas a bit? Less is sometimes better. No offense, really! Keep posting.Regarding keeping meta data on controller rather than transfer it with every message. ... There are of course both advantages and disadvantages with this approach.
If you are communicating directly between sensors in your network (without involving a controller) the meta data certainly makes a difference. Also when implementing simple The Arduino MQTT gateway (with limited resources) would also have a hard time without it.But I agree that transferring 5 bytes extra for describing the payload could be considered unnecessary sometimes. Especially for the more advanced controllers which easily could keep this info after an initial presentation. But maybe it could be worth the extra cost?
-
Looking at this as a retired programmer and experimenter, the amount of meta data could become vary large to support the maximum number of values, while almost all will be unused in a normal setup. A 1MByte SPI flash memory is cheap and easy to add to the gateway and will have storage for all of the needed data. More compact storage (linked list, etc.) become a potential update problem, particularly if several nodes are restarting at the same time (after a power failure), and all sending their presentation information.
I think that the configuration of a node should be in the node firmware, so only one control need to be changed when trying something new or changed. This requires the node to tell the gateway/controller what format and data type is being reported at presentation during node start up, or on request.
Based on these consideration - I suggest that the node description be sent at start up and at a request, and contain the data description and name string. This information is stored in a sparse table (fast Access) in flash memory on the gateway or smart controller. Reserve 3 bits for the action (presentation, set, report, get, system and future use), and 5 bits for the value number - 0 is the node, 1-30 data values, 31 reserved. This would give a total packet of 2 bytes destination - routing, 2 bytes data id, followed by 0-28 bytes of payload.
-
@Zeph
Trying to take in everything you've posted but it is quite hard to follow the long internal "discussions" and find the gems sometimes :). Could you perhaps try to summarize, and illustrate your ideas a bit? Less is sometimes better. No offense, really! Keep posting.Regarding keeping meta data on controller rather than transfer it with every message. ... There are of course both advantages and disadvantages with this approach.
If you are communicating directly between sensors in your network (without involving a controller) the meta data certainly makes a difference. Also when implementing simple The Arduino MQTT gateway (with limited resources) would also have a hard time without it.But I agree that transferring 5 bytes extra for describing the payload could be considered unnecessary sometimes. Especially for the more advanced controllers which easily could keep this info after an initial presentation. But maybe it could be worth the extra cost?
@hek
OK, point taken. I tend to describe in too much detail for this purpose.Short form:
-
Currently we send the V code (one byte), S code (one byte), child ID (one byte) and data format (a few bits) with every packet containing a variable. We could send those instead during the network joining process and use only a one byte "variable index" to replace all those OTA.
-
A core idea is to address a node (one byte) and a variable within a node (one byte zero based index). Every variable would have fixed metadata (like S code and V code and child_id) which is known to both sides (after the node joins the network) so it doesn't have to be sent each time.
-
However this approach allows us to expand (modestly) beyond the current S code and V code, and I think it allows us to get beyond some of the semantic confusion we get into by trying to pack too much into those two bytes.
How is that?
-
-
Looking at this as a retired programmer and experimenter, the amount of meta data could become vary large to support the maximum number of values, while almost all will be unused in a normal setup. A 1MByte SPI flash memory is cheap and easy to add to the gateway and will have storage for all of the needed data. More compact storage (linked list, etc.) become a potential update problem, particularly if several nodes are restarting at the same time (after a power failure), and all sending their presentation information.
I think that the configuration of a node should be in the node firmware, so only one control need to be changed when trying something new or changed. This requires the node to tell the gateway/controller what format and data type is being reported at presentation during node start up, or on request.
Based on these consideration - I suggest that the node description be sent at start up and at a request, and contain the data description and name string. This information is stored in a sparse table (fast Access) in flash memory on the gateway or smart controller. Reserve 3 bits for the action (presentation, set, report, get, system and future use), and 5 bits for the value number - 0 is the node, 1-30 data values, 31 reserved. This would give a total packet of 2 bytes destination - routing, 2 bytes data id, followed by 0-28 bytes of payload.
Your concern is large metadata. In a minimal implementation of this approach (keeping the current S and V code and a group ID which replaces the child ID), the hub would need to store those 3 bytes of metadata per variable.
Variables would be addressed within a node by a zero based index (ie: a compact array layout). In a minimal implemenations, when a node joins the network the gateway could see how many variables the node has (1 byte) and allocate an array of 3*N bytes to store tne metadata for that node.
What's a reasonble size network? How about 50 nodes with an average of 5 variables each? That's well under a kbyte of RAM for metadata.
So if you were using an ATMega328p for the gateway and you wanted to support that many nodes, it might begin to stress your RAM, especially if we expand the metadata beyond that minimum (used for napkin estimates).
But if I had 50 nodes I'd be using a $20 Teensy 3.1 with 64K of RAM (or a $25 DUE clone with 96K), which could handle it easily. And for 15 nodes, say, even an ATMega328p might be enough.
That said, if we did expand the metadata to include a name or brief description, that could push the RAM needs a bit further. That would need to be optional metadata, available to gateways but not required.
-
@Zeph
Trying to take in everything you've posted but it is quite hard to follow the long internal "discussions" and find the gems sometimes :). Could you perhaps try to summarize, and illustrate your ideas a bit? Less is sometimes better. No offense, really! Keep posting.Regarding keeping meta data on controller rather than transfer it with every message. ... There are of course both advantages and disadvantages with this approach.
If you are communicating directly between sensors in your network (without involving a controller) the meta data certainly makes a difference. Also when implementing simple The Arduino MQTT gateway (with limited resources) would also have a hard time without it.But I agree that transferring 5 bytes extra for describing the payload could be considered unnecessary sometimes. Especially for the more advanced controllers which easily could keep this info after an initial presentation. But maybe it could be worth the extra cost?
@hek said:
Regarding keeping meta data on controller rather than transfer it with every message. ... There are of course both advantages and disadvantages with this approach.
If you are communicating directly between sensors in your network (without involving a controller) the meta data certainly makes a difference.Let's explore that.
As I see it, the core data transfer functionality of the sensor network consists of sending the current values of variables to and from sensactuator nodes. Each node has some number of such variables.
Suppose there's are two variables containing the current temperature and humidity from a given DHT-11 (one of several sensors in that node). How are those specific variables "addressed" or identified as distinct from other variables in the same node?
In the latest proposal, the "identity" of those variables might be:
Node = 6 Child = 2, S code = S_TEMPERATURE, V code = V_LEVEL.and
Node - 6 Child = 2 S code = S_HUMIDITY V code = V_PERCENTAGEIf you change the S code or V code (or child), you are no longer referring to the same variable. So S code and V code are both metadata AND part of the addressing/identity for that variable. (And you can't have two variables of the same type in the same child).
In the new proposal, addressing or identity might be:
Node = 6 VariableIdx = 6and
Node = 6 VariableIdx = 7This is pure addressing. Metadata (S and V codes, or enhancements of them) is kept separate and transmitted only once during network joining (if at all).
OK?
Suppose that node 3 wants to display that temp and humidity, and let's use the currently proposed S and V codes as the metadata for apples to apples.
Now, how would one node know how to communicate directly with another node, without involving the hub/controller/gateway? Node 3 would not inherently know that node 6 exists, or which child within node 6 has the required temperature and humidity - unless you program that information into node 3. And/or program node 6 to send its information to node 3.
Case 1: Node 3 knows that the temp to display has identity/address:
Node 6 Child 1 S code S_TEMPERATURE V code V_LEVELCase 2: node 3 knows that the temp to display has address:
Node 6 VariableIdx 0and it could just as well continue to know that for that variable has metadata:
S code S_TEMPERATURE V code V_LEVELIn either case node 3 can know the S and V code, tho in the former those are part of the address and in the latter they are metadata.
Or if node 6 just sends its reports to node 3, it could send metadata with each packet or separately. We can examine that case too, but I don't see it as any show stopper.
Also when implementing simple The Arduino MQTT gateway (with limited resources) would also have a hard time without it.
Could you explain that a bit more? Are you saying that MQTT cannot route well using only node id and variable idx, and that it needs to be able to interpret S and V codes for each packet in flight? If anything I'd think the simpler addressing without S and V would take less resources but I'm not familiar with the internals so I'm guessing.
-
@hek
OK, point taken. I tend to describe in too much detail for this purpose.Short form:
-
Currently we send the V code (one byte), S code (one byte), child ID (one byte) and data format (a few bits) with every packet containing a variable. We could send those instead during the network joining process and use only a one byte "variable index" to replace all those OTA.
-
A core idea is to address a node (one byte) and a variable within a node (one byte zero based index). Every variable would have fixed metadata (like S code and V code and child_id) which is known to both sides (after the node joins the network) so it doesn't have to be sent each time.
-
However this approach allows us to expand (modestly) beyond the current S code and V code, and I think it allows us to get beyond some of the semantic confusion we get into by trying to pack too much into those two bytes.
How is that?
@Zeph said:
How is that?
:thumbsup: Much better :)
Yes, a variableindex is a classical solution for minimizing storage. I've used googles protocol buffer a few times which is a excellent solution for packing structured data. But I'm not fully convinced we should increase the complexity for a byte of saved data which very well could help out in other cases.
Now, how would one node know how to communicate directly with another node, without involving the hub/controller/gateway? Node 3 would not inherently know that node 6 exists, or which child within node 6 has the required temperature and humidity - unless you program that information into node 3. And/or program node 6 to send its information to node 3.
Many people use "hardcoded" node ids and direct communication without any controller/gateway involved. To have them accept presentations and create/store variable indexes would probably be too much effort.
We could also (in the future) support some kind of find-node-with-certain-sensor-attached broadcast message. To locate all temperature sensors in the radio network.
So what I'm saying is that we must be able to handle a gateway/controller-less setup also without too much fuss.
-
-
@Zeph said:
How is that?
:thumbsup: Much better :)
Yes, a variableindex is a classical solution for minimizing storage. I've used googles protocol buffer a few times which is a excellent solution for packing structured data. But I'm not fully convinced we should increase the complexity for a byte of saved data which very well could help out in other cases.
Now, how would one node know how to communicate directly with another node, without involving the hub/controller/gateway? Node 3 would not inherently know that node 6 exists, or which child within node 6 has the required temperature and humidity - unless you program that information into node 3. And/or program node 6 to send its information to node 3.
Many people use "hardcoded" node ids and direct communication without any controller/gateway involved. To have them accept presentations and create/store variable indexes would probably be too much effort.
We could also (in the future) support some kind of find-node-with-certain-sensor-attached broadcast message. To locate all temperature sensors in the radio network.
So what I'm saying is that we must be able to handle a gateway/controller-less setup also without too much fuss.
Now, how would one node know how to communicate directly with another node, without involving the hub/controller/gateway? Node 3 would not inherently know that node 6 exists, or which child within node 6 has the required temperature and humidity - unless you program that information into node 3. And/or program node 6 to send its information to node 3.
@hek said:
Many people use "hardcoded" node ids and direct communication without any controller/gateway involved. To have them accept presentations and create/store variable indexes would probably be too much effort.
But if you are now hard coding the node id and child id, you could just as easily be hard coding the node ID and variable idx instead, no?
You only have to accept presentations if you want to be dynamically configured. If you want to hard code the V code and S code (metadata) you can do that in either case.
So what I'm saying is that we must be able to handle a gateway/controller-less setup also without too much fuss.
I may still be missing something because it seems like we are reducing the fuss by treating V code, S code and (if needed Child/group ID) as pure metadata rather than as both metadata and address/identity.
Or perhaps I'm talking about a little deeper restructuring than I'm yet conveyed to you, and the emergent simplicity is obscured by not yet seeing what falls out.
I'm open to either possibility. Let's first assume that I'm missing something.
Any further thoughts about the MQTT question? I do want to be compatible with that, so your concern about that is something I want to understand and address.
-
@hek @Zeph
No I don't like the idea that the gateway should remember stuff about the sensors. If should be just a gateway. So it is not only about MQTT gateway but serial / ethernet gateway too. We could have a meta transportation command to transport your meta data from node via gateway to controller that handles all the magic stuff. But this will only lead to yet another byte used up in the set/req. which doesn't actually matter. for most value types 20bytes is enough for almost anything.. :)
And why everyone is so afraid of missing one byte or 3 or 6 is weird, The discussion about the protocol is to have different commands. there some commands have more header data about the payload and other might have none (just transportation header + payload)..
And yes ofc we could add isp flash and stuff but this will make the gateway not being a gateway any longer...And the mqtt address is at the moment nodeid/sensorid/datatype. next version will have nodeid/sensorid/sensortype(text)/valuetype(text) and because I know at the controller I have the ability to use # at sensor id so I could get data via only names S_TEMP/V_VALUE ie.. and IF I am going to store anything at all is is the NODE NAME. and this will probably fill the available memory up. ofc we could go with a more expensive MCU also.. but like I already said , The gateway should be simple. It would be nice to be able to address something with MQTT/#/base_wash/#/S_Humid/V_Value. .. and maybe skip number ass together. Only to identify the mqtt address with only number, sure that would work, but it would look like a mess. :) if we have predefined types, just send those with the payload and we know what w are dealing with!
-
@hek @Zeph
No I don't like the idea that the gateway should remember stuff about the sensors. If should be just a gateway. So it is not only about MQTT gateway but serial / ethernet gateway too. We could have a meta transportation command to transport your meta data from node via gateway to controller that handles all the magic stuff. But this will only lead to yet another byte used up in the set/req. which doesn't actually matter. for most value types 20bytes is enough for almost anything.. :)
And why everyone is so afraid of missing one byte or 3 or 6 is weird, The discussion about the protocol is to have different commands. there some commands have more header data about the payload and other might have none (just transportation header + payload)..
And yes ofc we could add isp flash and stuff but this will make the gateway not being a gateway any longer...And the mqtt address is at the moment nodeid/sensorid/datatype. next version will have nodeid/sensorid/sensortype(text)/valuetype(text) and because I know at the controller I have the ability to use # at sensor id so I could get data via only names S_TEMP/V_VALUE ie.. and IF I am going to store anything at all is is the NODE NAME. and this will probably fill the available memory up. ofc we could go with a more expensive MCU also.. but like I already said , The gateway should be simple. It would be nice to be able to address something with MQTT/#/base_wash/#/S_Humid/V_Value. .. and maybe skip number ass together. Only to identify the mqtt address with only number, sure that would work, but it would look like a mess. :) if we have predefined types, just send those with the payload and we know what w are dealing with!
@Damme said:
No I don't like the idea that the gateway should remember stuff about the sensors. If should be just a gateway.
Hmmm. Seems like the gateway or the controller HAVE to remember stuff about the sensors in any case. Otherwise how do they know the address/identity of the temperature and humidity that the living room DHT-11 provide?
All we currently have to remember is that those sensors have address/identity:
Node ID Child ID S Code V CodeIf you fail to remember any of that, you cannot identify or address those variables, right?
Now imagine for a moment that while the gateway or controller must remember all four of those items, they can identify/address the given variables OTA with only two (ie: the latter two values do not need to be sent in every packet referencing the given variable). There's nothing new to remember that you were not already remembering - but you just don't need to send all of your remembered data in each packet.
(And you are remembering a variable idx rather than a child id, but to the gateway either one is just an arbitrary 8 bit number it has been told to associate with the given variable).
What am I missing here? Thanks for your patience.
-
I will take my controller as an example:
Node ID, The address of the node
Child ID The sensor on this node
S Code one of the possible more variables send on behave of the sensor node
V code the variable type of the send valueI HAVE to remember those so it can be linked together, so if i receive a value it has to be linked to a var type, from which i can say is possible to only send while presenting..
On my controller side it is possible to leave the V Code out (but a device then MUST present itself), but all the others should stay.
If there would be an arbitrary number to identify it it should be decoded again to match it to the node id, with the sensor id and s code. But that then would be in my controllers case.
-
Let me be clear about something. The proposal is largely about cleanly separating static metadata about a variable from the identity/addressing of that variable, not about saving bytes in the packet.
Compared to the the current proposed with S and V codes as both metadata and address/identity, the proposed alternative of transferring those static values during setup rather than with each packet does have the small advantage of saving two bytes. But that's not the motivation or main payoff.
Let me give an example of where it might pay off. Suppose that after a while we realized that it would be useful to pass brightness values which are not expressed in Lux because we have no way to calibrate a given sensor. The current S and V codes only allow brightness to be expressed in Lux. So we could add a new S code for non-Lux brightness. And a new S code for non-dB sound loudness. And a new code for any uncalibrated measurement which is just like the normal measurment but not available in standard units.
But suppose instead we wanted just one bit of semantics: the values reported for this sensor are not in the standard units, but they do measure the same thing. Then this bit of information could be equally associated with any variable of any type, without adding new codes.
We could add that bit to the OTA packet format so that the node would convey that bit of semantics every time it reports a brightness (is this calibrated to standard units or not?). Depending on where that bit was inserted into the packet format, all nodes might need to be modified to use the new packet layout, even if they are calibrated.
Or, with the separated metadata approach, a node could convey that new information just once during setup. The OTA Set command format doesn't change at all. And a node which uses only calibrated unit variables doesn't change at all (the default remains "calibrated"). A node that does have uncalibrated veriables is modified to pass that flag during setup. Done.
I see this as a need-to-know design issue, not unlike using protected member variables in a class is a design issue. You should design the users of a class so that they do not need to directly understand the implementation of the class, so that you can later change that implementation without cascading effects on all the users of that class.
Likewise the mechanism for sending the dynamic current value of a variable from point A to point B should be cleanly partitioned from the static metadata needed to describe and interpret that value, so that you can later modify or add to the static metadata without implications for the simple transporting of a dynamic current value. There is a clean need-to-know partitioning between the concepts of static metadata about a variable and dynamic current values, which I strongly believe will pay off in many ways as the design continues to evolve in months and years to come.
I believe that conflating static metadata with the addressing needed to identify a given variable is going to be an ongoing source of semantic and structural confusion. Any later tweaks to the metadata to address newly recognized shortcomings or add functionality will have cascading effects in parts of the protocol (eg variable value transport) which logically would not need to change.
At least that's my current design sense.
-
Here's an example of the kind of metadata that might be passed from a node when it joins the network (using the approach advocated in this thread).
(The term "variable" is a little too generic and easily confused with other variables. I'm going to start calling these things Network Accessible Variables or NAVs.)
NUM_NAV = number of NAVs implemented by this node (addressed 0..NUM_NAV-1)and then for each NAV there would be a metadata sequence of 3 or more non-zero bytes terminated with a zero byte:
S code (1..255) chosen from S_LIST V code (1..255) chosen from V_LIST Child Id (1.255) grouping container Zero or more A codes (each 1..255) chosen from A_LIST 0 byte terminating the metadata for this NAVThe optional attribute codes in the A_LIST could include concepts like "uncalibrated units" or "WaterTemperature" that modify the interpretation of the values reported or set for the associated NAV. The absence of a given A code in the metadata means "use the default interpretation" - like "reported in standard units" or "free air temperature".
Any A code that is not understood can be ignored.
Is that hard to describe, understand or implement? Is it a large amount of data to store, transport or remember?
Example metadata definition in the node:
uint8_t mymeta[] = { 3, // number of NAVs S_TEMPERATURE, V_LEVEL, 1, 0, // NAV 0 metadata S_HUMIDITY, V_PERCENTAGE, 1, 0, // NAV 1 metadata S_BRIGHTNESS, V_LEVEL, 2, A_UNCALIBRATED, 0 // NAV 2 metadata };Here's another node with two DHT-11's (they can communicate for some distance over wire so one might be inside and one outside, or intake and exhaust of a swamp cooler or whatever)
uint8_t mymeta[] = { 4, // NUM_NAV S_TEMPERATURE, V_LEVEL, 1, 0, // NAV 0, first DHT-11 S_HUMIDITY, V_PERCENTAGE, 1, 0, // NAV 1 S_TEMPERATURE, V_LEVEL, 2, 0, // NAV 2, second DHT-11 S_HUMIDITY, V_PERCENTAGE, 2, 0 };Note that the "child id" groups the variables from each DHT-11 together (as each pair represent the highly related temp and humidity at the same location). This reflects the use of child-id as a container for related variables as @hek pointed out me to a few days ago.
I'm not proposing that this be the final version; it's just for illustration of concepts and how they can be very simple.
-
@hek @Zeph
No I don't like the idea that the gateway should remember stuff about the sensors. If should be just a gateway. So it is not only about MQTT gateway but serial / ethernet gateway too. We could have a meta transportation command to transport your meta data from node via gateway to controller that handles all the magic stuff. But this will only lead to yet another byte used up in the set/req. which doesn't actually matter. for most value types 20bytes is enough for almost anything.. :)
And why everyone is so afraid of missing one byte or 3 or 6 is weird, The discussion about the protocol is to have different commands. there some commands have more header data about the payload and other might have none (just transportation header + payload)..
And yes ofc we could add isp flash and stuff but this will make the gateway not being a gateway any longer...And the mqtt address is at the moment nodeid/sensorid/datatype. next version will have nodeid/sensorid/sensortype(text)/valuetype(text) and because I know at the controller I have the ability to use # at sensor id so I could get data via only names S_TEMP/V_VALUE ie.. and IF I am going to store anything at all is is the NODE NAME. and this will probably fill the available memory up. ofc we could go with a more expensive MCU also.. but like I already said , The gateway should be simple. It would be nice to be able to address something with MQTT/#/base_wash/#/S_Humid/V_Value. .. and maybe skip number ass together. Only to identify the mqtt address with only number, sure that would work, but it would look like a mess. :) if we have predefined types, just send those with the payload and we know what w are dealing with!
@Damme said:
No I don't like the idea that the gateway should remember stuff about the sensors. If should be just a gateway.
I have thought some more about this, and I think there are multiple viable ways to organize a sensor network.
-
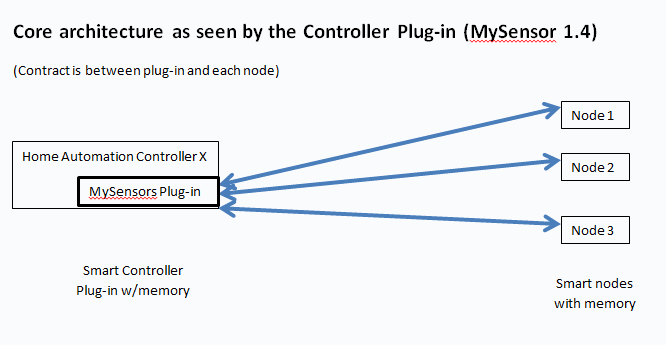
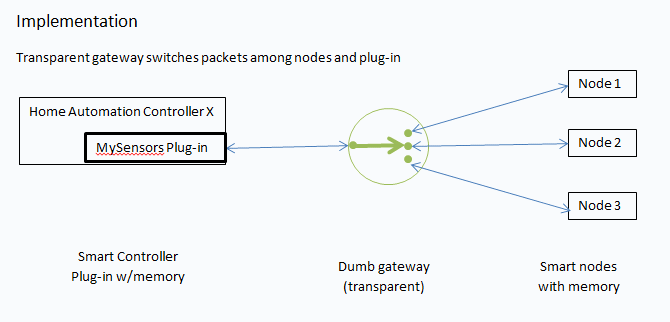
I understand that your preferred model is that all of the smarts of the wireless sensor network per se exists in the nodes themselves - and the "API" is a contract between the end nodes and the HA controller software. Any gateway is just a transport mechanism, as transparent as possible. The "gateway" node is just a switchboard for packets,along with the minimal additional functionality to make things work (like address assignment).
-
I have been conceptualizing the API contract more as being between the "gateway" node and the HA Controller; the gateway makes use of sensor nodes to accomplish its task. This expanded concept of a "gateway" would allow the gateway to do more controlling,, optimizing, translating, and enhancing.
As an example, the enhanced gateway could know all the variables available from each connected sensacturator node via saving some startup metadata. It could hide some version changes from the HA controller.
Suppose we had added "decimal point scaling" metadata, so that a node could report that its MHT-22 measured a temp of 29.1 degrees as the integer 291 with a metadata scaling factor of 1 (divide by 10 to get the standard units). Versus sending the value as a 4 byte float with the hint that it's meaningful to one decimal place. The point is it could report both of those to the HA controller as 29.1 degrees, doing the translation itself. This allows more details of the OTA protocol to be transparent to the HA Controller - information hiding. And that means that when there are several HA controller adapters (eg: plug-ins) in several languages from several authors, the WSN architecture can evolve without creating unneccessary dependencies within each HA controller plug-in. That gateway hides any aspect of the WSN that the HA controller plug-in doesn't logically need to understand.
Of course some level of major changes to the WSN's internal architecture or protocols will have to be reflected in the HA controllers' plug-in, but the more the enhanced gateway hides unnecessary details, the less often that will happen.
Another thing to node is that the enhanced gateway could answer some queries about a battery powered node from the HA controller plug-in, even between wakup times. Like metadata queries (what variables does it have, using which S and V codes), or the most recent value reported and when. Or it could queue up commands, to be passed to the node when it powers on and contacts the enhanced gateway.
Note that this "enhanced gateway" conceptualization can still include the same transparent switching functionality; it just leaves open the idea that there is also a translation layer between the switch and the WSN API as seen by the various HA controller plug-ins.
I find this model of an enhanced gateway very attractive. The details of what it does and doesn't do can evolve, but it has flexibility to do things which the nodes cannot. The main 'downside' is that when a WSN system gets large, the gateway may need to cost another $10 for more capable hardware, mainly for more RAM tho more program memory and speed usually comes with that too. But I'm going to predict that within a couple of years most gateways will be running on cheap ARM chips rather than AVRs anyway, especially for larger WSN networks. If your 30 nodes have cost you $800, upgrading the hub for $10 to make the programming and maintenance is going to be an easy choice. (or use a RPi directly for a bit more cost).
AND - there's also something to be said for keeping the gateway node's functionality minimal, as you envision it. I'm not discounting that.
The two approaches just trade off complexity and flexibility in different areas of the design. We sweep the complexity from one corner of the building to another, based on where we intuit that will bring the best results down the road.
By this time next year, I think we'll be seeing some of the way these appraoches pan out. At this time so much is about intuition of which path will turn out better, rather than solid deductive logic, so it's a judgment all rather than being "right" vs "wrong".
-
-
I really like this proposal.
What it would give us:
- Multiple variables of the same type (like two temperatures)
- The possibility for human description of a variable (core temp, air temp, engine temp)
- The possibility to describe the values even if they don't exist (Say if temperature didn't exist we could describe it as a LEVEL with the unit °C
- The possibility to describe the range of values (I.E. This temp may be between 0-25°C)
This doesn't need to be handled by the gateway, it could be moved to the controller which usually are a high-performance device. And if it isn't (doesn't have room to store the configuration) it may ask the node for it every time it receives a value from the node. In this configuration the gateway would just be a translator between nrf24 and USB, or nrf24 and Ethernet or whatever.